1,600 days of a failed hobby data science project
Comments
"The data collection process involved a daily ritual of manually visiting the Tagesschau website to capture links"
I don't know what to say... I'm amazed they kept this up so long, but this really should never have been the game plan.
I also had some data science hobby projects around covid; I got busy, lost interest after 6 months. But the scrapers keep running in the cloud, in case I get motivated again (anyone need structured data on eBay listings for laptops since 2020?), that's the beauty of automation for these sorts of things.
I don't speak the language so maybe what you're scraping isn't in this list, but why manual when they seem to have comprehensive RSS feeds? [1]
Automating this part should have been day 1.
The author’s right about storytelling from day one, but then immediately throws cold water on the idea by saying it would have been a bad fit for this project.
This feels in error, as the big value of seeking feedback and results early and often on a project is that it forces you to confront whether you’re going to want or be able to tell stories in the space at all. It also gives you a chance to re-kindle waning interests, get feedback on your project by others, and avoid ratholing into something for about 5 years without having to engage with a public.
If a project can’t emotionally bear day one scrutiny, it’s unlikely to fare better five years later when you’ve got a lot of emotions about incompleteness and the feeling your work isn’t relevant anymore tied up in the project.
The title seems misleading. Unless I'm missing something, all he did was scrape a news feed, which should only require a couple days of work to set up.
The fact that he left it running for years without finding the time to do anything with the data isn't that interesting.
What I love about projects like this is they are dynamic enough to cover a number of interests all in one.
I personally have some side projects that have started as X, transitioned into Y and Z, and then I stole some ideas and built A, which turned to B, which a requirement in my professional job necessitated the Z solution mixed with the B solution and resulted in something else which re-ignited my interest in X and helped me rebuild with a more clear mindset on what I intended in the first place.
All that to say, these things are dynamic and a long list of "failed" projects is a historical narrative of learning and interests over time. I love to see it.
"Data Science Project Failing After 1,600 Days"
Sounds like my Thesis.
How many people have spent 4+ years on a Thesis then just completely gave up, tired, drained, no interest in continuing. The bright eye'd bushy tailed wonder, all gone.
Nice article OP. I and a great many others suffer from the same struggles of bringing personal projects to “completion”, and I’ve gotta respect the resilience in the length of time you hung in there. However, not to be overly pedantic, but I always felt “data science” was an exploratory exercise to discover insights into a given data set. I always personally filed the efforts to create the pipeline and associated automation (i.e. identify, capture, and store a given data set - more commonly referred to as “ETL”) as a “data engineering” task, which these days is considered a different specialty. Perhaps if you scope your problem a little smaller, you may yet be able to capture something demonstrably valuable to others (and something you might consider “finished”). You’d be surprised how simple something that addresses a real issue can be to be able to provide real value for others.
Nice work and great effort.
> The data collection process involved a daily ritual of manually visiting the Tagesschau website to capture links to both the COVID and later Ukraine war newstickers. While this manual approach constituted the bulk of the project’s effort, it was necessitated by Tagesschau’s unstructured URL schema, which made automated link collection impractical.
> The emphasis on preserving raw HTML proved vital when Tagesschau repeatedly altered their newsticker DOM structure throughout Q2 2020.
Another big takeaway is that it's not sustainable to rely on this type of a data source. Your data source should be stable. If the site offers API's, that's almost always better than parsing html.
Website developers do not consider scrapers when they make changes. Why would they? So if you are ever trying to collect some unique dataset, it doesn't hurt to reach out to the web devs to see if they can provide a public API.
Anyone knows what software is used to create these diagrams: https://lellep.xyz/blog/images/failed_data_science_project/2...
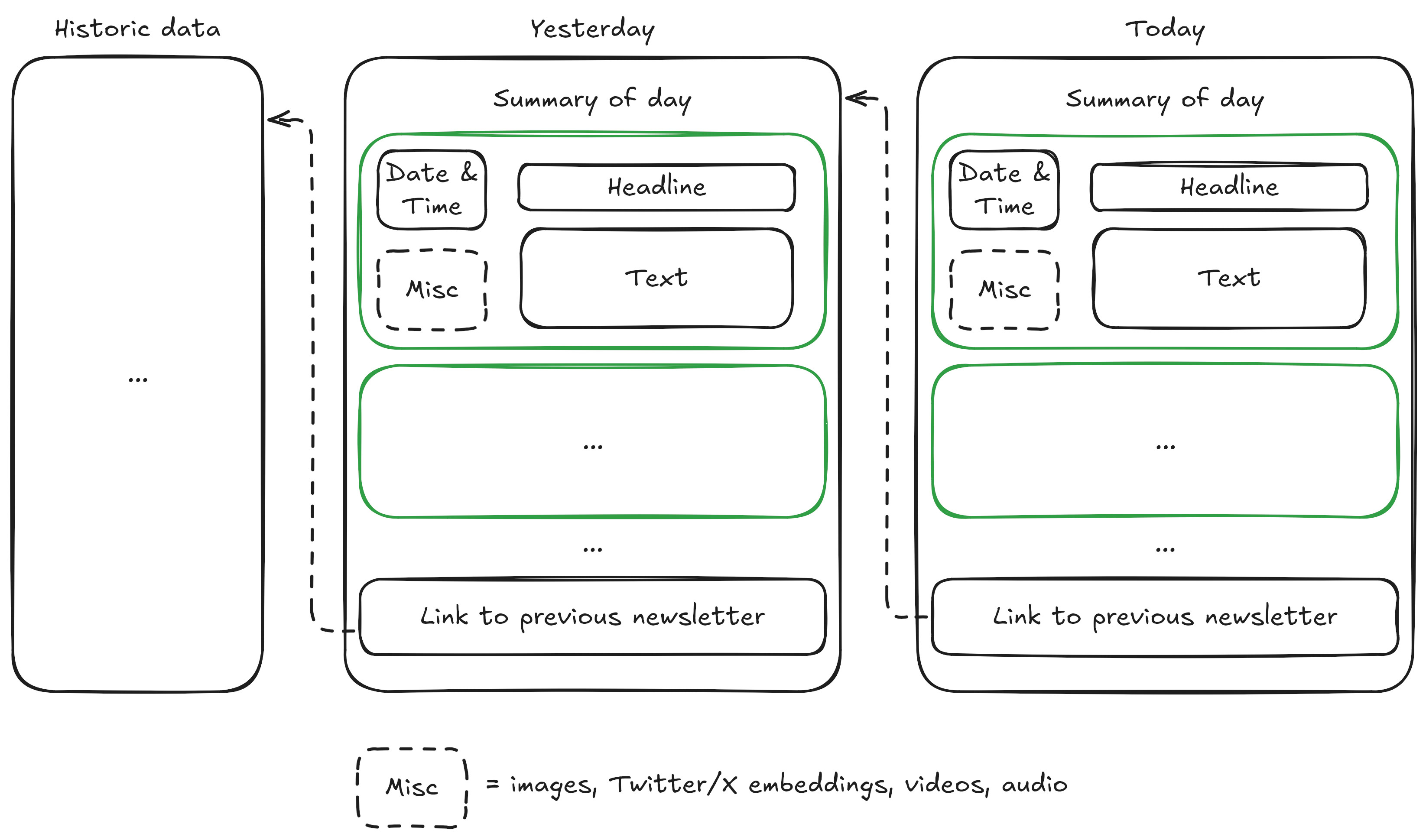{kind=link}
Why not open source? I've been slaving away at some possibly pointless data scraping sites that collect app data and the SDKs that apps use. I figure if I at least open source it that data and code is there for others to use.
I see some recommendations about running a small version of the analysis first to see if it's going to work at all. I agree, and the next level up is to also estimate the value of performing the full analysis. I.e. not just whether or not it will work at all, but how much it is allowed to cost and still be useful.
You may find, for example, that each unit of uncertainty reduced costs more than the value of the corresponding uncertainty reduction. This is the point at which one needs to either find a new approach, or be content with the level of uncertainty one has.
I think whether you 'succeed' or 'fail' on a side project they are still valuable. No matter if you can't finish it or it turns out different to how you imagined -- you get to come away as a better version of yourself. A person who is more optimized for a new strategy. And sometimes 'failure' is a worthwhile price for that ability. Who knows, it might be exactly what prepares you for something even bigger in the future.
> Store raw data if possible. This allows you to condense it later.
I have some daily scripts reading from an http endpoint, and I can't really decide what to do when it returns html instead of json. Should I store the HTML as it is "raw data" or should I just dismiss it? The API in question has a tendency to return 200 with a webpage saying that the API can't be reached (typically because of a time out)
I don’t know that projects ever fail.
Doing them and learning and growing from them is the point.
They shed a light on your path and also what you are able to see as possible.
I know the feeling. I managed 9 months scraping supermarket data before I gave up mostly because a few other people were doing it and I was short on time.
Oh boy, the topic (Covid) alone would have left me exhausted after a few months. I heard enough of it by mid 2021.
Turns out it wasn't nearly as much as 1600 days of labor. So, clickbait headline.
People relatively new to CS would be wise to be warned about what a colossal time sink it is.
the last thing the world or rather germany needs is a news ticker based on ... the tagesschau LOL
I for one don't want to start counting everything I lose interest in as a "failure", that would be too depressing. I actually think this is a feature not a flaw. You have very few attention tokens and should be aggressive in getting them back.
I think this is very different from the "finishing" decision. That should focus on scope and iterations, while attempting to account for effort vs. reward and avoiding things like sunk cost influences.
Combine both and you've got "pragmatic grit": the ability to get valuable shit done.
I still don't understand what he even tried to do? So he manually collected news articles for a few years without any plan on what to do with them so what? Where is the project? Honestly he could probably just have asked the tagesschau people and they would have given him their archive. The learning from this seems to be: collecting data and never doing anything with it is not a worthy project
Some very weird things in this.
1. The title makes it sound like the author spent a lot of time on this project. But really, this mostly consisted of noting down a couple of URLs per day. So maybe 5 min / day = ~130h spent on the project. Let's say 200h to be on the safe side.
2. "Get first analyses results out quickly based on a small dataset and don’t just collect data up front to “analyse it later”" => I think this actually killed the project. Collecting data for several years w/o actually doing anything doesn't with it is not a sound project.
3. "If I would have finished the project, this dataset would then have been released" ==> There is literally nothing stopping OP from still doing this. It costs maybe 2h of work and would potentially give a substantial benefit to others, i.e., turn this project into a win after all. I'm very puzzled why OP didn't do this.
[dead]
I’m not sure I would call this a failure.. more just something you tried out of curiosity and abandoned. Happens to literally everyone. “Failed” to me would imply there was something fundamentally broken about the approach or the dataset, or that there was an actual negative impact to the unrealized result. It’s very hard to finish long-running side projects that aren’t generating income, attention, or driven by some quasi-pathological obsession. The fact you even blogged about it and made HN front page qualifies as a success in my book.
> If I would have finished the project, this dataset would then have been released and used for a number of analyses using Python.
Nothing stopping you from releasing the raw dataset and calling it a success!
> Back then, I would have trained a specialised model (or used a pretrained specialised model) but since LLMs made so much progress during the runtime of this project from 2020-Q1 to 2024-Q4, I would now rather consider a foundational model wrapped as an AI agent instead; for example, I would try to find a foundation model to do the job of for example finding the right link on the Tagesschau website, which was by far the most draining part of the whole project.
I actually just started (and subsequently —-abandoned—- paused) my own news analysis side project leveraging LLMs for consolidation/aggregation.. and yeah, the web scraping part is still the worst. And I’ve had the same thought that feeding raw HTML to the LLM might be an easier way of parsing web objects now. The problem is most sites are privy to scraping efforts and it’s not so much a matter of finding the right element but bypassing the weird click-thru screens, tricking the site that you’re on a real browser, etc…