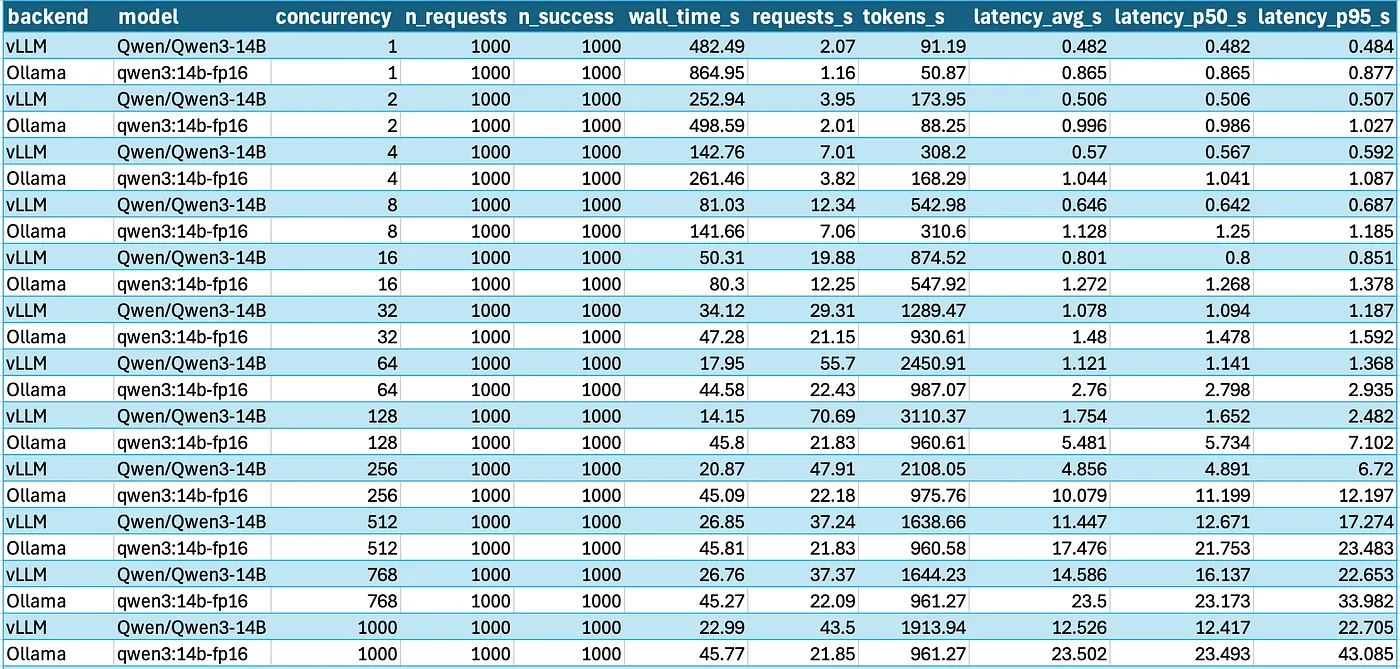
Any speed up that is 2x is definitely worth fixing. Especially since someone has already figured out the issue and performance testing [1] shows that llamacpp* is lagging behind vLLM by 2x. This is a positive for all running LLMs locally using llamacpp.
Even if llamacpp isnt used for batch inference now, this can allow those to finally run llamacpp for batching and on any hardware since vLLM supports only select hardware. Maybe finally we can stop all this gpu api software fragmentation and cuda moat as llamacpp benchmarks have shown Vulkan to be as or more performant than cuda or sycl.
[1] https://miro.medium.com/v2/resize:fit:1400/format:webp/1*lab...
{kind=link}
So, what exactly is batch inference workload and how would someone running inference on local setup benefit from it? Or how would I even benefit from it if I had a single machine hosting multiple users simultaneously?
I believe batching is a concept only useful when during the training or fine tuning process.