Curious about the training data of OpenAI's new GPT-OSS models? I was too
Comments
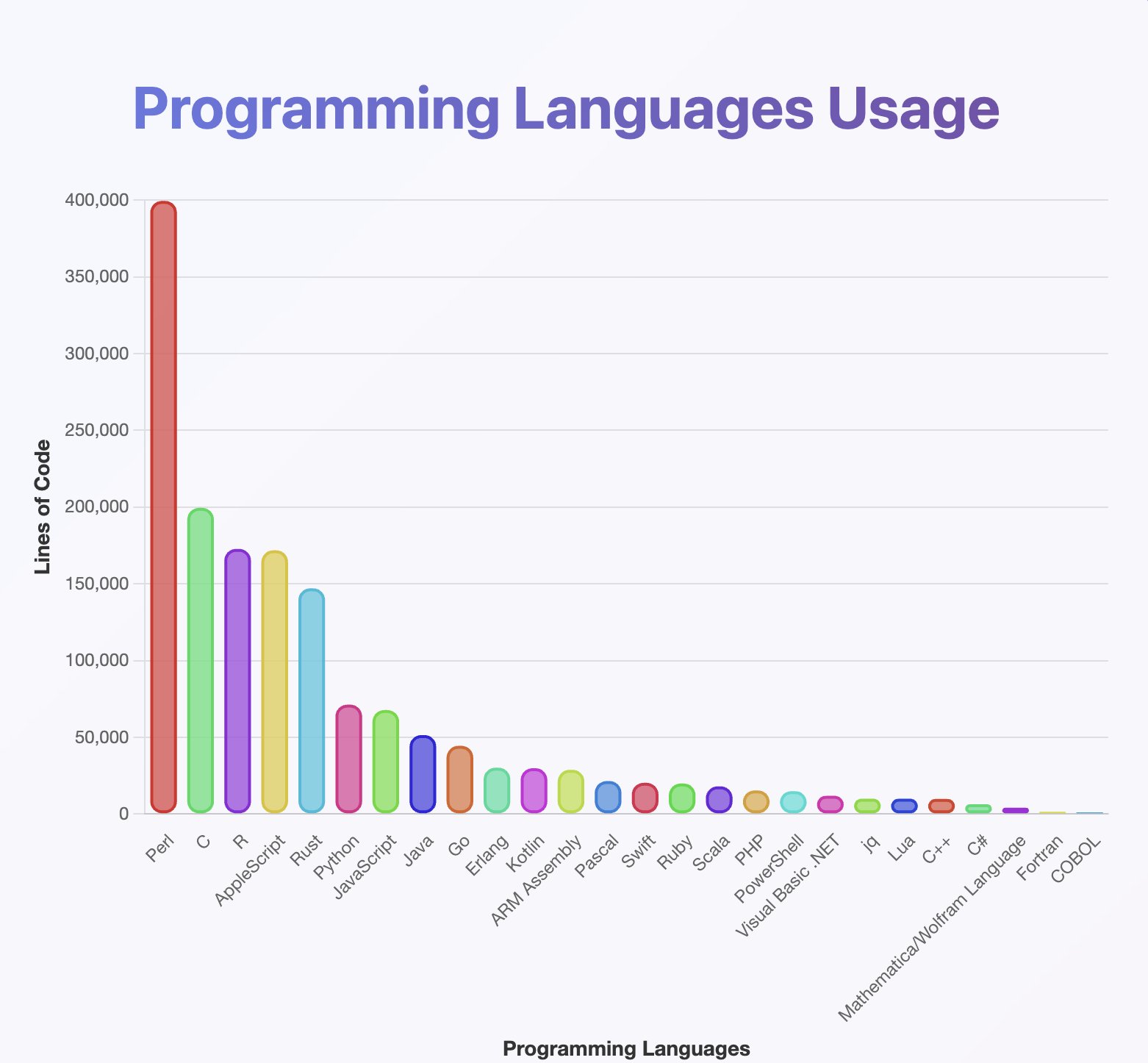
OP seems to have run a programming language detector on the generated texts, and made a graph of programming language frecuencies: https://pbs.twimg.com/media/Gx2kvNxXEAAkBO0.jpg?name=orig
{kind=link}
As a result, OP seems to think the model was trained on a lot of Perl: https://xcancel.com/jxmnop/status/1953899440315527273#m
LOL! I think these results speak more to the flexibility of Perl than any actual insight on the training data! After all, 93% of inkblots are valid Perl scripts: https://www.mcmillen.dev/sigbovik/
Anything but this image (imgbb.com link below) requires a login. I get the same deal with Facebook. I am not Don Quixote and prefer not to march into hell for a heavenly cause, nor any other.
{kind=link}
>what you can't see from the map is many of the chains start in English but slowly descend into Neuralese
That's just natural reward hacking when you have no training/constraints for readability. IIRC R1 Zero is like that too, they retrained it with a bit of SFT to keep it readable and called it R1. Hallucinating training examples if you break the format or prompt it with nothing is also pretty standard behavior.
This looks very interesting but I don't really understand what he has done here. Can someone explain the process he has gone through in this analysis?
"this thing is clearly trained via RL to think and solve tasks for specific reasoning benchmarks. nothing else." Has the train already reached the end of the line?
> the chains start in English but slowly descend into Neuralese
What is Nueralese? I tried searching for a definition but it just turns up a bunch of Less Wrong and Medium articles that don't explain anything.
Is it a technical term?
I don't know how to get a unwalled version. What's the best way to do that these days? xcancel seems unavailable.
Presumably the model is trained in post-training to produce a response to a prompt, but not to reproduce the prompt itself. So if you prompt it with an empty prompt it's going to be out of distribution.
> OpenAI has figured out RL. the models no longer speak english
What does this mean?
What does that mean ?
5 seems to do a better job with copyrighted content. I got it to spit out the entirely of ep IV (but you have to redact the character names)
[dead]
Not very rigorous or scientific, honestly, I would say it's just clickbait spam with some pretty graphs. Everything on twitter is now a "deep dive". No info on how the 10M "random examples" were generated and how that prevents the model from collapsing around variations of the same output. Others already mentioned how the "classification" of output by coding language is bunk with a good explanation for how Perl can come out on top even if it's not actually Perl, but I was struck by OP saying "(btw, from my analysis Java and Kotlin should be way higher. classifier may have gone wrong)" but then merrily continuing to use the data.
Personally, I expect more rigor from any analysis and would hold myself to a higher standard. If I see anomalous output at a stage, I don't think "hmm looks like one particular case may be bad but the rest is fine" but rather "something must have gone wrong and the entire output/methodology is unusable garbage" until I figure out exactly how and why it went wrong. And 99 times out of a 100 it wasn't the one case (that happened to be languages OP was familiar with) but rather something fundamentally incorrect in the approach that means the data isn't usable and doesn't tell you anything.