I don't find this very compelling. If you look at the actual graph they are referencing but never showing [1] there is a clear improvement from Sonnet 3.7 -> Opus 4.0 -> Sonnet 4.5. This is just hidden in their graph because they are only looking at the number of PRs that are mergable with no human feedback whatsoever (a high standard even for humans).
And even if we were to agree that that's a reasonable standard, GPT 5 shouldn't be included. There is only one datapoint for all OpenAI models. That data point more indicative of the performance of OpenAI models (and the harness used) than of any progression. Once you exclude it it matches what you would expect from a logistic model. Improvements have slowed down, but not stopped
1: https://metr.org/assets/images/many-swe-bench-passing-prs-wo...
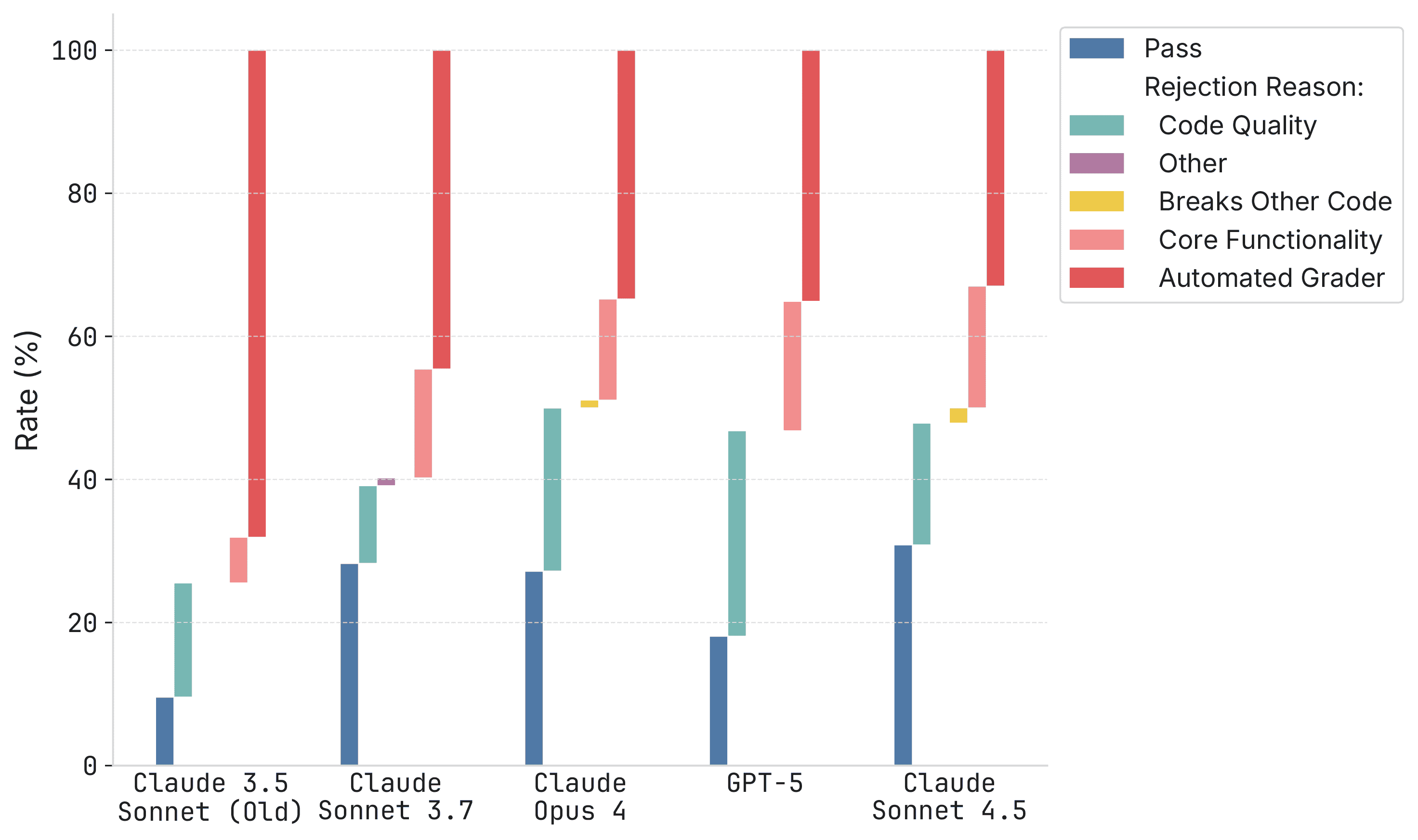{kind=link}
Replies
I don't know that graph to me shows Sonnet 4.5 as worse than 3.7. Maybe the automated grader is finding code breakages in 3.7 and not breaking that out? But I'd much prefer to add code that is a different style to my codebase than code that breaks other code. But even ignoring that the pass rate is almost identical between the two models.
Yes, I think this is basically an instance of the "emergent abilities mirage." https://arxiv.org/abs/2304.15004
If you measure completion rate on a task where a single mistake can cause a failure, you won't see noticeable improvements on that metric until all potential sources of error are close to being eliminated, and then if they do get eliminated it causes a sudden large jump in performance.
That's fine if you just want to know whether the current state is good enough on your task of choice, but if you also want to predict future performance, you need to break it down into smaller components and track each of them individually.