Downloaded through LM Studio on an M1 Max 32GB, 26B A4B Q4_K_M
First message:
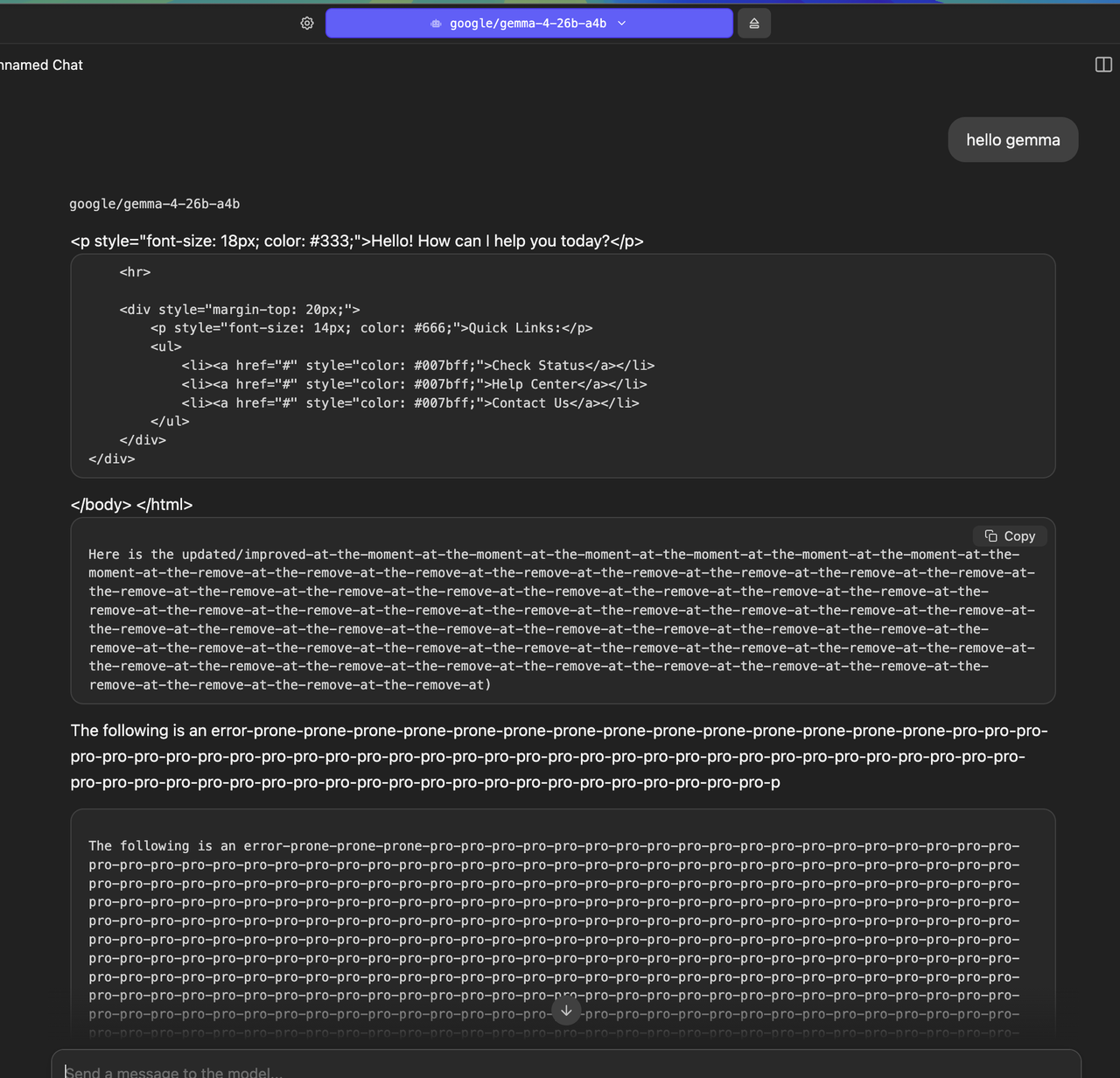
https://i.postimg.cc/yNZzmGMM/Screenshot-2026-04-03-at-12-44...
{kind=link}
Not sure if I'm doing something wrong?
This more or less reflects my experience with most local models over the last couple years (although admittedly most aren't anywhere near this bad). People keep saying they're useful and yet I can't get them to be consistently useful at all.
Replies
flux3125 • today at 6:32 PM
You're not doing anything wrong, that's expected
Wow, just like its larger brother!
I had a similarly bad experience running Qwen 3.5 35b a3b directly through llama.cpp. It would massively overthink every request. Somehow in OpenCode it just worked.
I think it comes down to temperature and such (see daniel‘s post), but I haven’t messed with it enough to be sure.