GPT Guesses Between 1 and 100
Comments
Is there a reason this was done with such a large sampling when you can read the logits one-shot?
I did this for an article, like so:
https://joecooper.me/blog/gptprimer/food.webp https://joecooper.me/blog/gptprimer/math.webp https://joecooper.me/blog/gptprimer/butts.webp
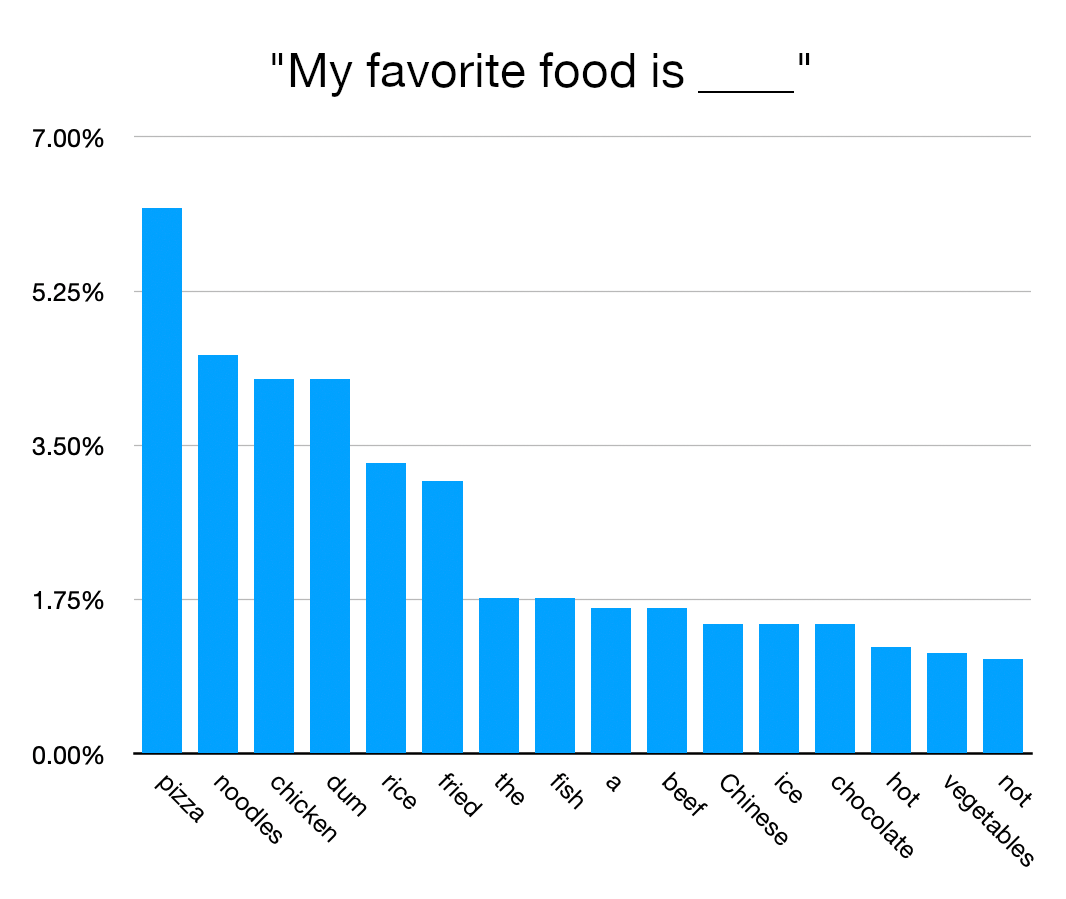{kind=link}
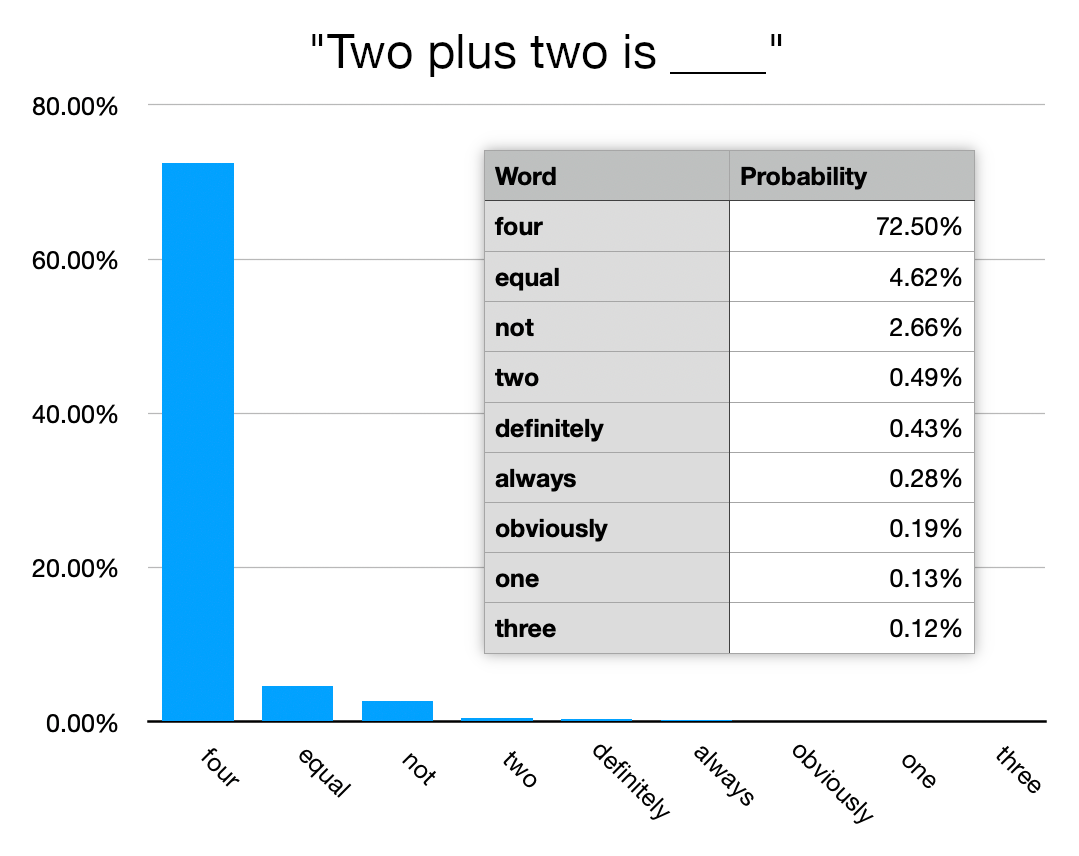{kind=link}
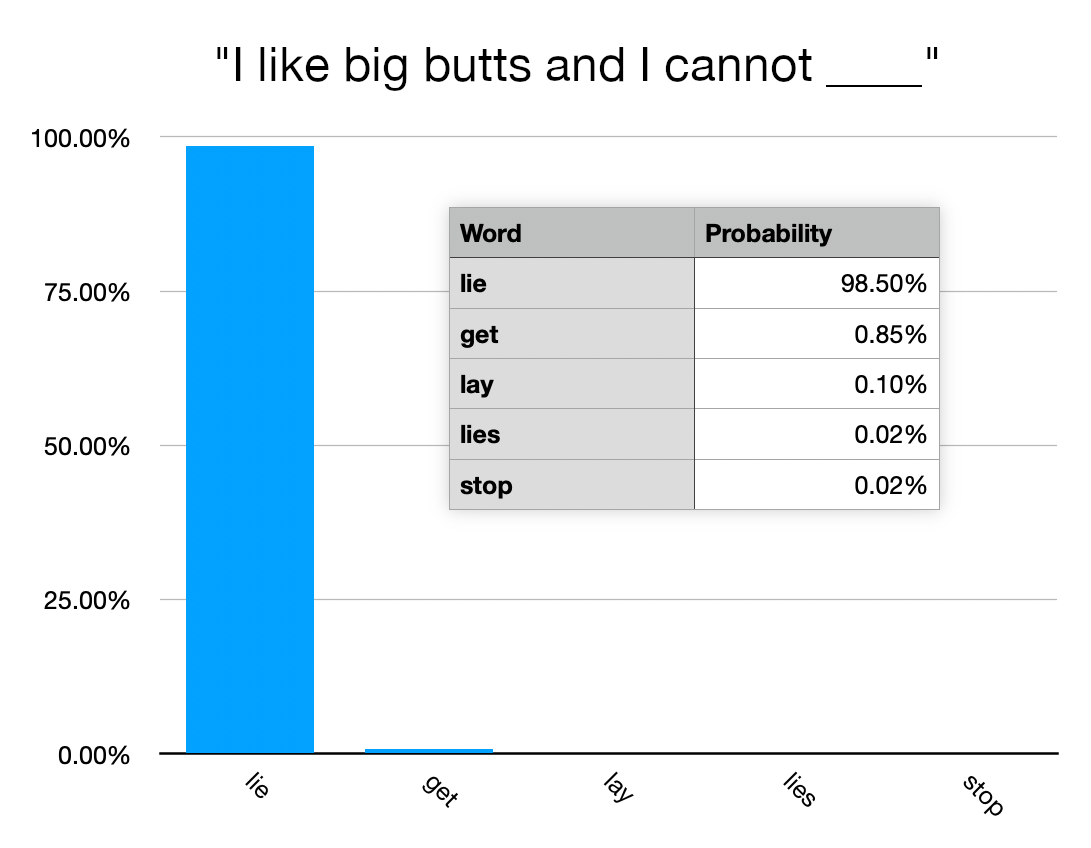{kind=link}
OpenAI removed this interface from their newer models, but IIRC you can still do this against 4.1 and 4o.
It could be an attack surface. Maybe one day, when we find a chatbot online, we could let it guess a random number repeatedly, then accurately infer the underlying model based on the resulting distribution.
Ask an AI to generate a image of random noise and you will be surprised.
Breaking: language model whose purpose is to predict the most likely token, after being trained on non-uniform human-generated dataset, does not follow a uniform distribution.
I'm still amazed that 37, 73, and other numbers ending in 7 are the most popular "random" choices for both AI and human. Check this Veritasium video for human choice: [Why is this number everywhere?](https://www.youtube.com/watch?v=d6iQrh2TK98)
In equally compelling results, my lawn mower does not cut grass to a uniformly random set of heights.
This is one of the many cases for LLMs that I ask for the intermediate work, e.g. a script that generates random numbers, instead of asking to do the work itself.
I attempted to scrape a one page grid with 800 items and also ended up asking for the Javascript look with document query selector instead of the result as I was hitting all sort of limits, context, or the LLM would do the wrong capture, print it out and get worse responses on next prompt.
I'm sure it's the logic layer handling that. Maybe even going to an external tool. It's not the llm.
> An interesting thing about humans is that they are not good random number generators. If you ask a person to "pick a random number between 1 and 100", they are remarkably predictable.
Stephen Colbert used to ask guests, as part of a joke questionnaire, “what number am I thinking of?”
Several numbers, especially “seven” came up a lot.
https://www.youtube.com/watch?v=hJ-fOj7Qqvs
The answer was “three”, by the way. Which you could deduce by seeing how he responded to that guess (usually “interesting” instead of “no”) but he also confirmed it on the last show.
"69 is a meme number", well no, 69 is innuendo. And sex = bad for bots. 67 is the meme number.
I wonder if Benford's law kicks in with larger numbers.
it shouldn't be hard to train GPT to output a flat distribution but it might not be worth it (I don't mean using tools)
Should be fun to play rock/paper/scissors against.
The premise is interesting, the question is brilliant, but the text. The text is a wall of ai slop saying almost nothing interesting. Fake profundity all throughout. GPT tell tells like "the hypothesis holds".
The hypothesis doesn't hold, because their isn't one.
You have an interesting question and interesting finding. Write about it! Think about it! Tell us about it! Don't just do the experiment and then wash your hands and sign off the explanation and findings to an LLM.
ha. and i thought 37signals was pretty random
I'm doing an experiment in Claude. When I set temperature to zero, I get 47 all the time.
Then I set temperature to 1.0 and used this prompt
>Pick a random integer between 1 and 100 inclusive. Respond with only the number, nothing else.
I still get 47 ten times out of ten.
Then I used this prompt
>Pick a random integer between 1 and 100 inclusive. I need you to maximise the randomness as far as possible. Respond with only the number, nothing else.
I get 3 unique values out of 10.
I've been meaning to do this for a while! Happy someone else spent the tokens...
It's much more random than I thought it would be. Never guessing 50 is very human though
bro 42 at 4x. the model read the whole internet and became a Douglas Adams fan.
The topic is vaguely interesting but I stopped reading a few paragraphs in because it's obviously AI generated.
While the results were not surprising, I found interesting that the number "69" was repressed in the output, so not even this kind of mathematical question escapes GPT censorship.
It appears that recognizing the effects of censorship is the easiest way to distinguish answers generated by an "AI' from those generated by a human.