Okay results are in for GenAI Showdown with the new gpt-image 1.5 model for the editing portions of the site!
https://genai-showdown.specr.net/image-editing
Conclusions
- OpenAI has always had some of the strongest prompt understanding alongside the weakest image fidelity. This update goes some way towards addressing this weakness.
- It's leagues better at making localized edits without altering the entire image's aesthetic than gpt-image-1, doubling the previous score from 4/12 to 8/12 and the only model that legitimately passed the Giraffe prompt.
- It's one of the most steerable models with a 90% compliance rate
Updates to GenAI Showdown
- Added outtakes sections to each model's detailed report in the Text-to-Image category, showcasing notable failures and unexpected behaviors.
- New models have been added including REVE and Flux.2 Dev (a new locally hostable model).
- Finally got around to implementing a weighted scoring mechanism which considers pass/fail, quality, and compliance for a more holistic model evaluation (click pass/fail icon to toggle between scoring methods).
If you just want to compare gpt-image-1, gpt-image-1.5, and NB Pro at the same time:
https://genai-showdown.specr.net/image-editing?models=o4,nbp...
Replies
This showdown benchmark was and still is great, but an enormous grain of salt should be added to any model that was released after the showdown benchmark itself.
Maybe everyone has a different dose of skepticism. Personally I'm not even looking at results for models that were released after the benchmark, for all this tells us, they might as well be one-trick ponies that only do well in the benchmark.
It might be too much work, but one possible "correct" approach for this kind of benchmark would to periodically release new benchmarks with new tests (that are broadly in the same categories) and only include models that predate each benchmark.
"Remove all the trash from the street and sidewalk. Replace the sleeping person on the ground with a green street bench. Change the parking meter into a planted tree."
What a prompt and image.
Love this benchmark, always the first place I look. Also seems like it is time to move the goalposts, not sure we are getting enough resolution between models anymore.
Out of curiosity why does gemini get gold for the poker example but gpt-image 1.5 does not? I couldn't see a difference between the two.
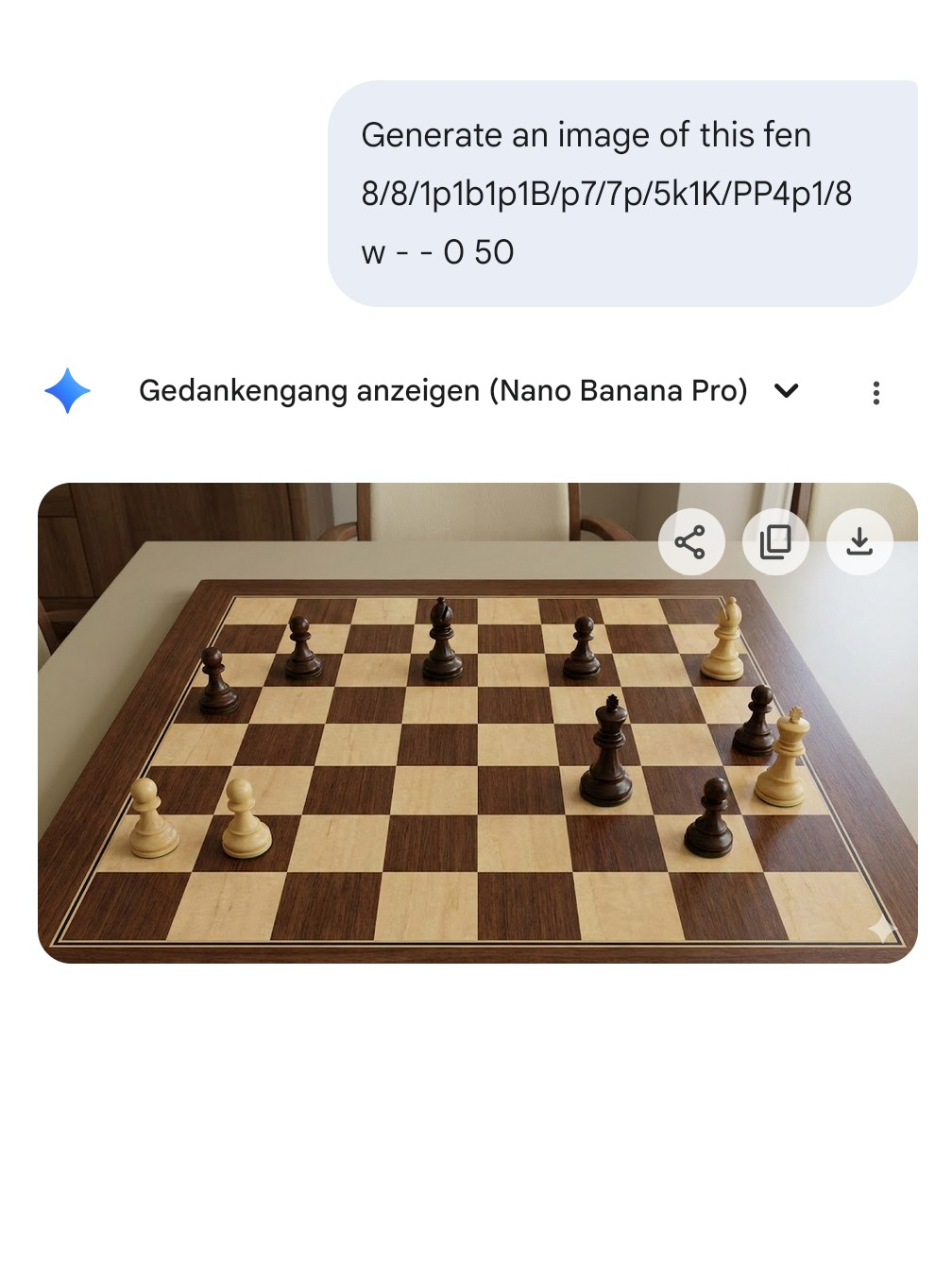
One other test you could add is generating a chessboard from a FEN. I was surprised to see NBP able to do that (however, it seems to only work with fewer pieces, after a certain amount it makes mistakes or even generates a completely wrong image) https://files.catbox.moe/uudsyt.png
{kind=link}
Z-image was released recently and that's what /r/StableDiffusion all talks about these days. Consider adding that too. It is very good quality for its size (Requires only 6 or 8 gigs of ram).
I disagree with gpt-image-1.5's grade on the worm sign. It moved some of the marks around to accommodate the enlarged black area, but retained the overall appearance of the sign.
GPT Image 1.5 is the first model that gets close to replicating the intricate detail mosaic of bullets in the "Lord of War" movie poster for me. Following the prompt instructions more closely also seems better compared to Nano Banana Pro.
I edited the original "Lord of War" poster with a reference image of Jensen and replaced bullets with GPU dies, silicon wafers and electronic components.
It failed my benchmark of a photo of a person touching their elbows together.
So when you say "X attempts" what does that mean? You just start a new chat with the same exact prompt and hope for a different result?
This leaderboard feels incredibly accurate given my own experience.
Stupid Cisco Umbrella is blocking you
Nano Banana has still the best VAE we have seen especially if you are doing high res production work. The flux2 comes close but gpt image is still miles away.
I really love everything you're doing!
Personal request: could you also advocate for "image previz rendering", which I feel is an extremely compelling use case for these companies to develop. Basically any 2d/3d compositor that allows you to visually block out a scene, then rely on the model to precisely position the set, set pieces, and character poses.
If we got this task onto benchmarks, the companies would absolutely start training their models to perform well at it.
Here are some examples:
gpt-image-1 absolutely excels at this, though you don't have much control over the style and aesthetic:
https://imgur.com/gallery/previz-to-image-gpt-image-1-x8t1ij...
Nano Banana (Pro) fails at this task:
https://imgur.com/a/previz-to-image-nano-banana-pro-Q2B8psd
Flux Kontext, Qwen, etc. have mixed results.
I'm going to re-run these under gpt-image-1.5 and report back.
Edit:
gpt-image-1.5 :
https://imgur.com/a/previz-to-image-gpt-image-1-5-3fq042U
And just as I finish this, Imgur deletes my original gpt-image-1 post.
Old link (broken): https://imgur.com/a/previz-to-image-gpt-image-1-Jq5M2Mh
Hopefully imgur doesn't break these. I'll have to start blogging and keep these somewhere I control.
> the only model that legitimately passed the Giraffe prompt.
10 years ago I would have considered that sentence satire. Now it allegedly means something.
Somehow it feels like we’re moving backwards.
Absolutely fabulous work.
Ludicrously unnecessary nitpick for "Remove all the brown pieces of candy from the glass bowl":
> Gemini 2.5 Flash - 18 attempts - No matter what we tried, Gemini 2.5 Flash always seemed to just generate an entirely new assortment of candies rather than just removing the brown ones.
The way I read the prompt, it demands that the candies should change arrangement. You didn't say "change the brown candies to a different color", you said "remove them". You can infer from the few brown ones that you can see that there are even more underneath - surely if you removed them all (even just by magically disappearing them) then the others would tumble down into a new location? The level of the candies is lower than before you started, which is what you'd expect if you remove some. Maybe it's just coincidence, but maybe this really was its reasoning. (It did unnecessarily remove the red candy from the hand though.)
I don't think any of the "passes" did as well as this, including Gemini 3.0 Pro Image. Qwen-Image-Edit did at least literally remove one of the three visible brown candies, but just recolored the other two.